数组
在算法中,数组 是最基础的数据结构,他用于表达在内存中,一段连续的存储空间。
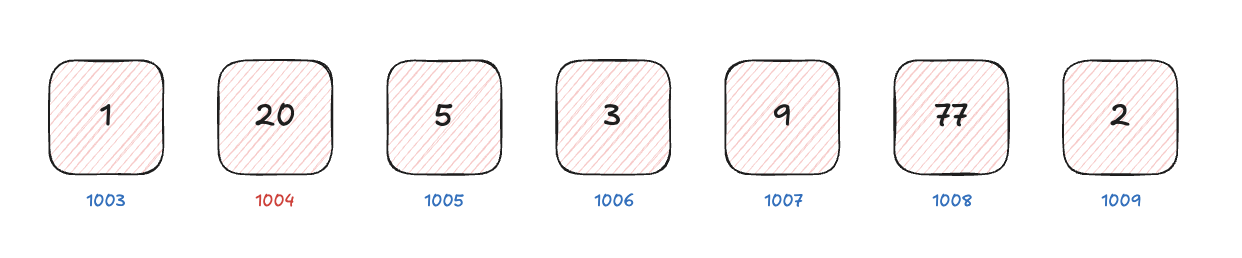
在学习数组时,我们要关注数组的如下几个特性
- 连续性 :数组的元素在内存中是连续的存储空间,因此我们可以通过索引快速访问数组中的任意元素
- 同质性 :在数组中,所有元素的类型都是相同的,这是因为数组在内存中是连续的存储空间,如果元素的类型不同,那么就无法确定每个元素所占用的内存大小,因此数组中的所有元素的类型都是相同的
- 大小固定 :大多数语言在声明数组时,会指定数组的大小,因此数组的大小是固定的,不能动态的增加或减少
由于其连续性的特性,因此我们访问数组元素时,时间复杂度为 ,访问速度特别快。
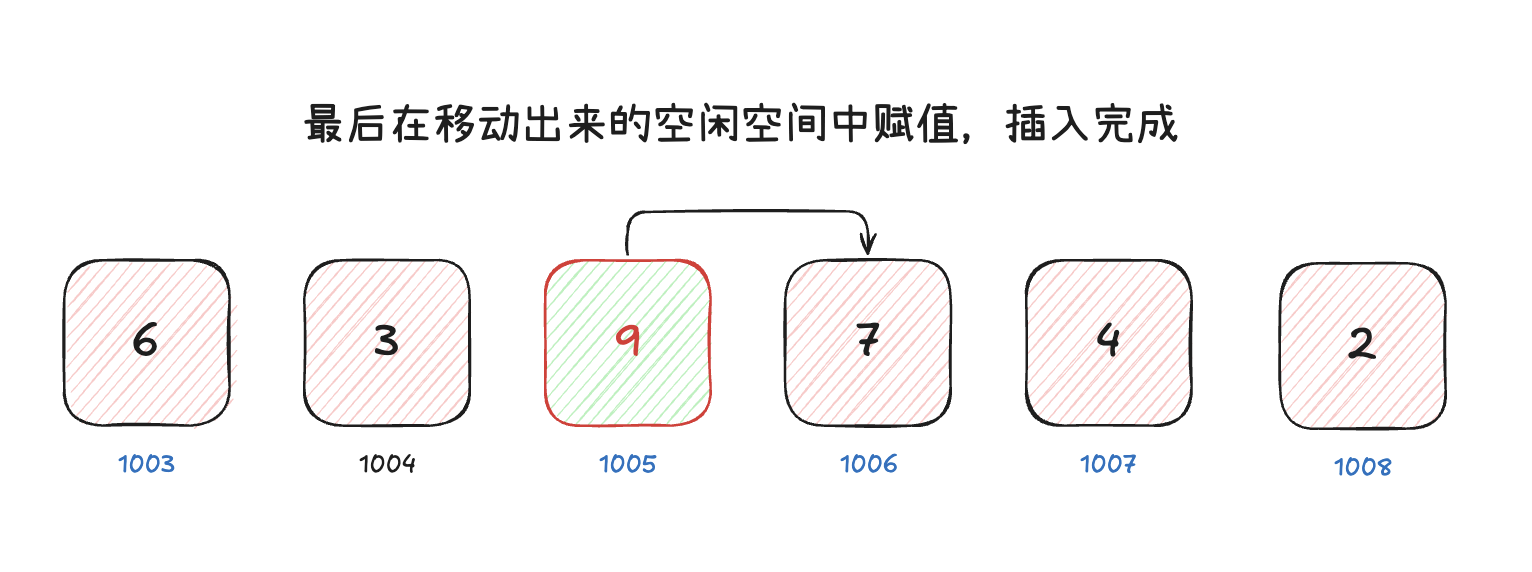
但是,由于其大小固定,因此我们插入和删除元素时,需要移动其他元素,因此速度较慢,时间复杂度为 。
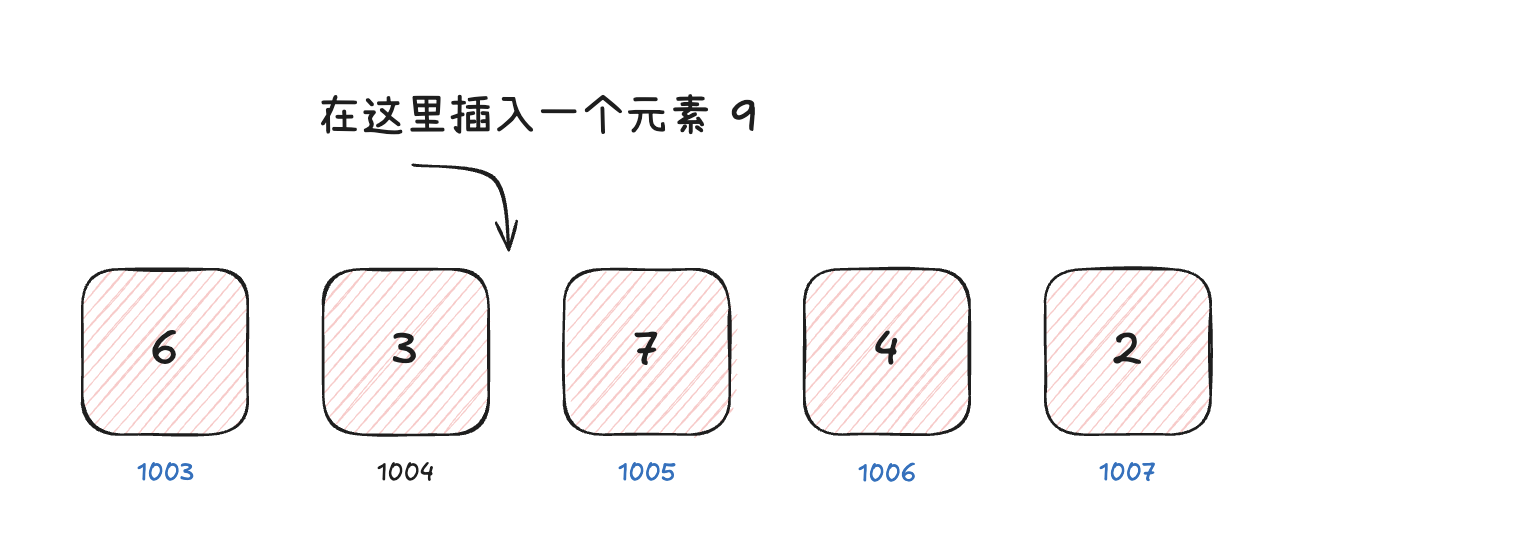
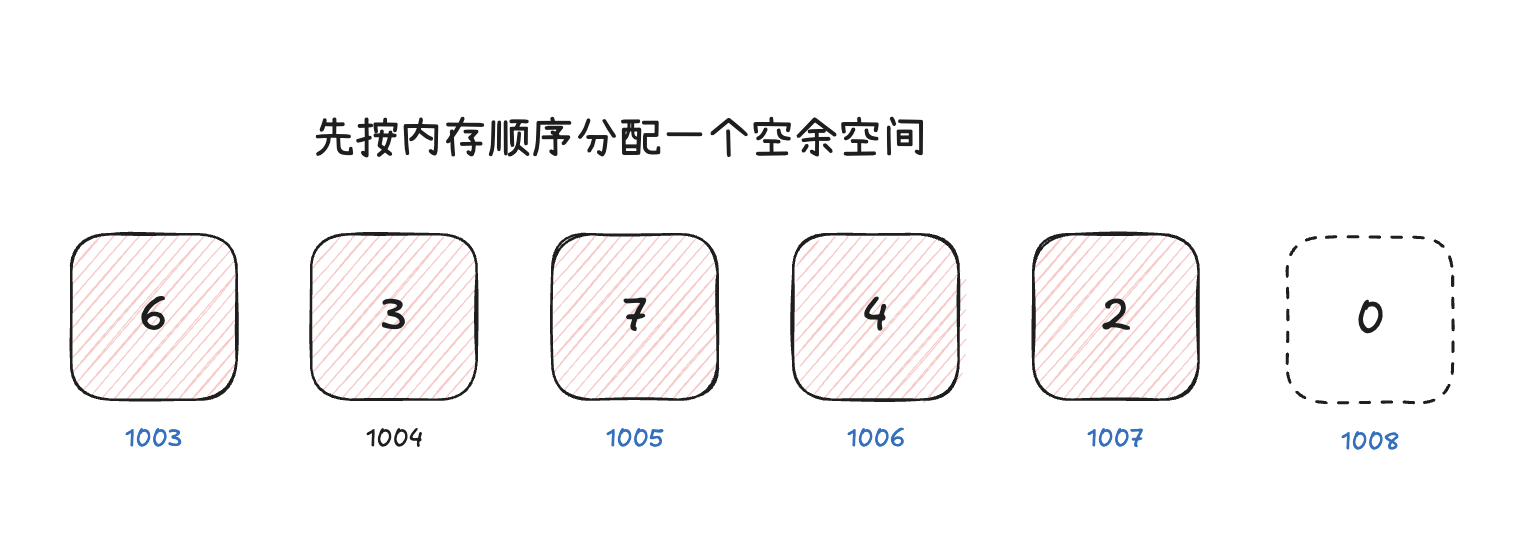
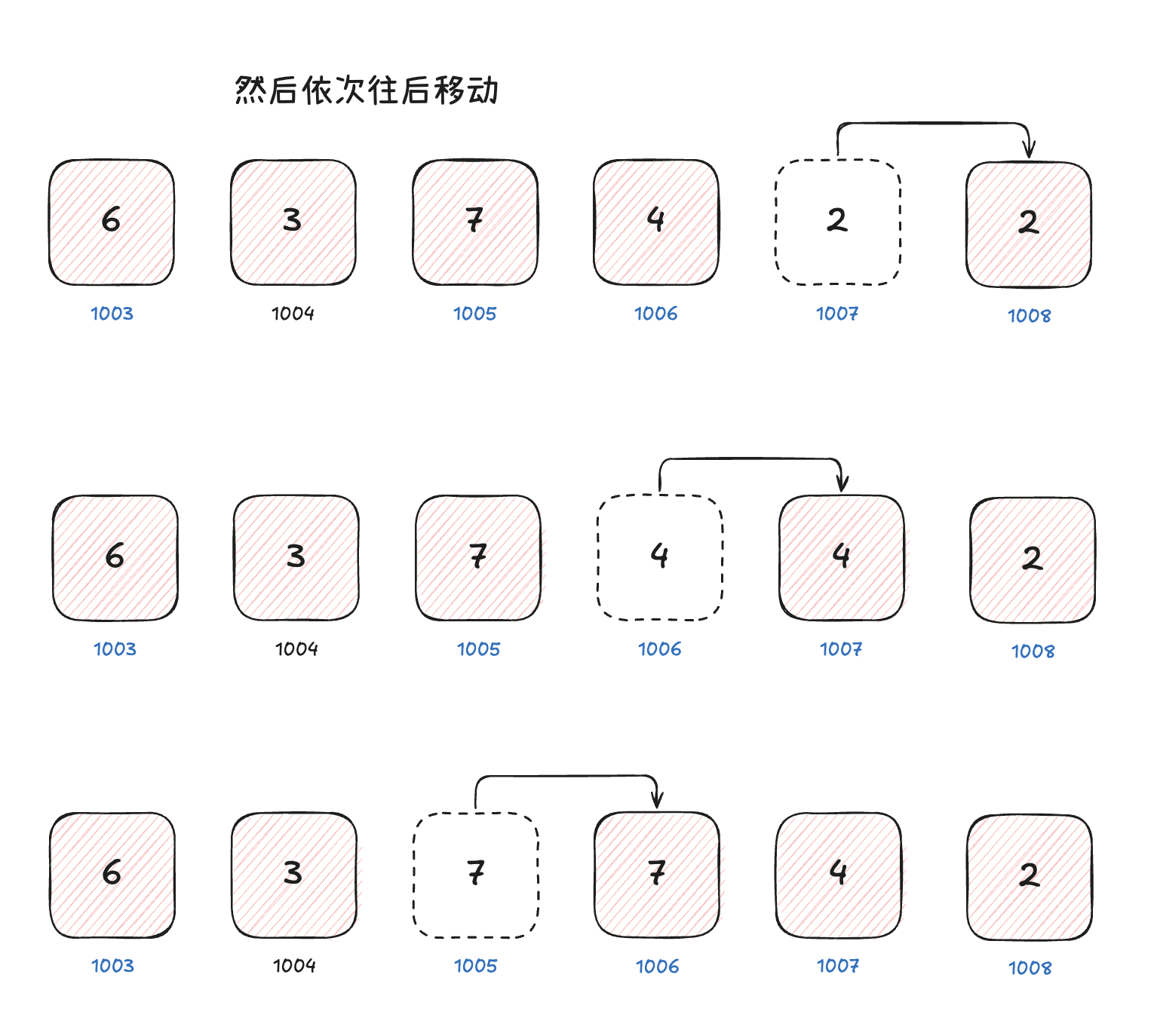
JavaScript 中的数组
为了确保数组具备足够的灵活性,在 JavaScript 中,数组被设计成为一个对象,他和其他开发语言的数组有所不同,其主要表现为
- 数组的大小不固定
- 数组中的元素类型可以不同
- 数组元素也可以不具备连续性
那么问题来了,我们应该如何看待 JavaScript 中的数组呢?
首先,我们要稍微科普一下,JavaScript 中的数组,在底层是如何实现的。在 V8 引擎的实现中,JavaScript 的数组包含两种形态
-
快数组
:
FixedArray,是一个连续的存储空间,与我们刚才学习的数组一样,具备连续性,同质性,大小固定等特性 -
慢数组
:
HashTable,是一个哈希表,是根据键值对存储的数据,不具备连续性,访问速度稍慢,接近 ,但是内存占用更灵活,操作效率更高
V8 引擎会根据不同的使用情况,在快数组和慢数组之间进行切换,以确保数组的使用效率。
默认情况下,我们创建一个普通数组时,V8 引擎会使用快数组。因此,大多数情况下,我们创建的数组,都是快数组。与算法中的数组保持了高度的一致性。但是,为了确保数组长度可以动态变化,JavaScript 中的数组,支持动态扩容,扩容的方式是:重新创建一个更大的快数组,并将原数组中的元素复制到新数组中 。
扩容后的新数组,空间是原数组的 1.5 倍 + 16,这个公式不需要记忆,只需要了解即可。
newCapacity
=
oldCapacity
+
(oldCapacity
>>
1
)
+
16
当新的空间再次不够用时,还会用同样的方式进行扩容。因此,当我们在使用数组的过程中,增加了数组的长度时,会对内存空间的消耗比较大 ,这是一种使用空间换取时间的实现方式
有如下几种方式会导致数组的存储方式从快数组转换为慢数组
1、扩容后,空闲内存空间大于 1024
个内存单位时,如下所示,此时存在大量的内存空洞,为了优化内存空间的利用率,会切换到慢数组
1
const
arr
=
[
1
,
2
,
3
,
4
,
5
]
2
// 此时,存在大量的空闲内存空间,会切换到慢数组,以节省内存空间
3
arr[
1040
]
=
6
2、V8 对快数组的索引有限制(2^32 - 1
),如果索引超过这个范围,会转为慢数组。
3、给数组添加非数字键(如 arr["foo "] = "bar "
),V8 会将其视为普通对象,转为慢数组。
4、数组长度被手动设置为极大值,为了避免空间浪费,会转为慢数组。
1
const
arr
= new
Array
(
1073741824
)
2
// 此时,数组的长度被手动设置为极大值,为了避免空间浪费,会转为慢数组
3
4
arr.
length
=
1073741824
虽然被称为慢数组,但是其实他的访问速度只是稍慢,因此,如果你发现你的场景需要非常频繁的插入和删除操作,那么刻意创建一个慢数组,可能最终会带来更大的收益
创建数组
我们可以通过如下的方式创建数组
10
// 此时,arr 是一个包含 1, 3, 2, 5, 4 的数组
20
const
arr
=
[
1
,
3
,
2
,
5
,
4
];
30
40
// 创建一个长度为 10 的数组,此时数组中的元素为空
50
const
arr
= new
Array
(
10
)
60
70
// 创建一个长度为 10 的数组,此时数组中的元素为 0
80
const
arr
= new
Array
(
10
).
fill
(
0
)
90
10
// 等价于 [1, 2, 3, 4, 5]
11
const
arr
=
Array.
of
(
1
,
2
,
3
,
4
,
5
)
12
13
// 等价于 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
14
const
arr
=
Array.
from
({length:
10
}, (
item
,
index
)
=>
index)
数组的操作方式
10
// 删除数组中的最后一个元素
20
arr.
pop
()
30
40
// 在数组末尾添加一个元素
50
arr.
push
(
6
)
60
70
// 删除数组中的第一个元素
80
arr.
shift
()
90
10
// 在数组的开头添加一个元素
11
arr.
unshift
(
0
)
我们也可以使用 splice
方法,在数组的指定位置添加或删除元素,此方法的使用稍微复杂一些,我们单独介绍
splice
方法的语法如下
arr.
splice
(start, deleteCount,
...
items)
-
start:表示在数组中的索引开始位置 -
deleteCount:从start开始计算,表示要删除的元素个数 -
...items:表示要添加的元素
1
// 从 index = 1 开始,删除 1 个元素,即删除 index = 1 的元素
2
arr.
splice
(
1
,
1
)
3
4
// 从 index = 1 开始,删除 1 个元素,并添加 2 个元素
5
arr.
splice
(
1
,
1
,
2
,
3
)
6
7
// 从 index = 1 开始,添加 1 个元素
8
// [3, 3, 3] =>[3, 2, 3, 3]
9
arr.
splice
(
1
,
0
,
2
)
遍历数组
由于数组的连续性,我们可以比较容易的通过定义一个索引指针,然后依次移动它,就可以遍历数组中的所有元素。语法上的表现就是循环
1
for
(
let
i
=
0
; i
<
arr.
length
; i
++
) {
2
console.
log
(arr[i])
3
}
更复杂的场景,我们会在后续的学习中逐步遇到,这里就不再赘述
手动对数组进行扩容
JavaScript 中底层对数组有自动扩容的机制,但是有的时候,面试中会遇到让我们手动对数组进行扩容的场景。在刚才,我们已经介绍过数组扩容的安全方式:创建一个更大的内容空间,并将原数组中的元素复制到新数组中。
这个算法的基本操作,我们也需要掌握,时间复杂度为 ,代码如下所示
10
// 传入原数组,与扩容后的新长度
20
function
expandArray
(
arr
:
number
[],
newLength
:
number
) {
30
// 创建一个更大的数组
40
const
newArr
= new
Array
(newLength)
50
// 将原数组中的元素复制到新数组中
60
for
(
let
i
=
0
; i
<
arr.
length
; i
++
) {
70
newArr[i]
=
arr[i]
80
}
90
// 返回新数组
10
return
newArr
11
}
练习题:合并两个非递减数组
给你两个按非递减顺序排列的整数数组 nums1
和 nums2
,另有两个整数 m
和 n
,分别表示 nums1
和 nums2
中的元素数目。
请你合并 nums2
到 nums1
中,使合并后的数组同样按非递减顺序排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1
中。为了应对这种情况,nums1
的初始长度为 m + n
,其中前 m
个元素表示应合并的元素,后 n
个元素为 0
,应忽略。nums2
的长度为 n
。
1
输入:nums1
=
[
1
,
2
,
3
,
0
,
0
,
0
], m
=
3
, nums2
=
[
2
,
5
,
6
], n
=
3
2
输出:[
1
,
2
,
2
,
3
,
5
,
6
]
3
解释:需要合并 [
1
,
2
,
3
] 和 [
2
,
5
,
6
] 。
4
合并结果是 [
1
,
2
,
2
,
3
,
5
,
6
] ,其中斜体加粗标注的为 nums1 中的元素。
解题思路一
由于已经存在的两个数组,是按非递减顺序排列的,因此,我们可以定义一个中间数组,将两个数组中的元素依次放入到中间数组中,然后依次从中间数组中取出元素,放入 nums1
中。
然后分别定义两个索引指针,用于指向 nums1
和 nums2
中的元素,通过循环移动指针的过程中,将较小的元素放入到中间数组中。
这里需要注意的是 nums1
传入的特殊格式,nums1
数组的长度是 m + n
,其中前 m
个元素是有效元素,后 n
个元素是无效元素,用 0
填充,因此,在移动指针的过程中,需要判断指针是否已经到达了有效元素的末尾。
nums1 = [1,2,3,0,0,0]
基于这个考虑,我们的代码实现如下所示
10
function
merge
(
nums1
:
number
[],
m
:
number
,
nums2
:
number
[],
n
:
number
) {
20
// 定义一个临时数组,这里最好创建一个长度为 `m + n` 的数组,避免执行过程中自动扩容,从而造成更大的内存浪费和时间浪费
30
const
temp
=
[]
40
// 定义两个指针,分别指向 `nums1` 和 `nums2` 中的有效元素,从 0 开始
50
let
p1
=
0
60
let
p2
=
0
70
80
// 循环移动指针,将较小的元素放入到中间数组中
90
while
(p1
<
m
||
p2
<
n) {
10
// 如果 `nums1` 的指针已经到达了有效元素的末尾,则将 `nums2` 中的元素放入到中间数组中
11
if
(p1
===
m) {
12
temp.
push
(nums2[p2])
13
p2
++
14
}
else if
(p2
===
n) {
15
// 如果 `nums2` 的指针已经到达了有效元素的末尾,则将 `nums1` 中的元素放入到中间数组中
16
temp.
push
(nums1[p1])
17
p1
++
18
}
else if
(nums1[p1]
<
nums2[p2]) {
19
// 如果 `nums1` 中的元素小于 `nums2` 中的元素,则将 `nums1` 中的元素放入到中间数组中
20
temp.
push
(nums1[p1])
21
p1
++
22
}
else
{
23
// 如果 `nums2` 中的元素小于 `nums1` 中的元素,则将 `nums2` 中的元素放入到中间数组中
24
temp.
push
(nums2[p2])
25
p2
++
26
}
27
}
28
29
// 将中间数组中的元素放入 `nums1` 中
30
for
(
let
i
=
0
; i
<
temp.
length
; i
++
) {
31
nums1[i]
=
temp[i]
32
}
33
}
- 时间复杂度:
- 空间复杂度:
解题思路二
在上面,我们创建了一个临时数组,用于存储合并后的元素。但是由于 nums1
数组的长度是 m + n
,其中前 m
个元素是有效元素,后 n
个元素是无效元素,用 0
填充,因此,我们也可以直接在 nums1
中进行操作,这样就可以避免创建临时数组,从而节省空间。
不过,为了不覆盖已经存在的有效元素,我们需要把对比出来的有效元素,从 nums1
的末尾开始放置。因此,这里的循环需要从后往前遍历。
基于这个考虑,我们的代码实现如下所示
10
function
merge
(
nums1
:
number
[],
m
:
number
,
nums2
:
number
[],
n
:
number
) {
20
let
i
=
m
+
n
-
1
;
30
// 和上一方案相比,进一步优化判断条件
40
while
(n
>
0
) {
50
// 取更大的值,填充到 `nums1` 的末尾
60
if
(m
>
0
&&
nums1[m
-
1
]
>
nums2[n
-
1
]) {
70
nums1[i]
=
nums1[m
-
1
];
80
i
--
;
90
m
--
;
10
}
else
{
11
nums1[i]
=
nums2[n
-
1
];
12
i
--
;
13
n
--
;
14
}
15
}
16
}
- 时间复杂度:
- 空间复杂度:
总结
数组是算法中最基础的数据结构之一。他具有访问效率高、但插入和删除效率可能会比较低 的特点。在后续的章节中,我们还会遇到大量的数组相关的题目,希望大家可以熟练掌握数组的基本操作,为后续的学习打下坚实的基础。